/prod01/wlvacuk/media/departments/digital-content-and-communications/images-2024/Diane-Spencer-(Teaser-image).jpg)
/prod01/wlvacuk/media/departments/digital-content-and-communications/images-18-19/220325-Engineers_teach_thumbail.jpg)
/prod01/wlvacuk/media/departments/digital-content-and-communications/images-2024/241024-Dr-Christopher-Stone-Resized.jpg)
/prod01/wlvacuk/media/departments/digital-content-and-communications/images-2024/241014-Cyber4ME-Project-Resized.jpg)
/prod01/wlvacuk/media/departments/digital-content-and-communications/images-2024/240315-Research-Resized.jpg)
Data sharing, reuse, and citation: current practices, challenges, and recommendations

Data sharing, reuse, and citation: current practices, challenges, and recommendations
Data collection is an integral part of research in most disciplines. Sharing research data in a meaningful and accessible manner allows reproducibility and reusability, promotes collaboration, and enables the answering of novel research questions. However, differences in data types and formats, varied data sharing cultures between disciplines, and ethical issues with sensitive data make the ecosystem of research data a complex one. It involves multiple stakeholders: researchers, data repository staff, journal editors, funders, and technology developers, where each have an important role to play.
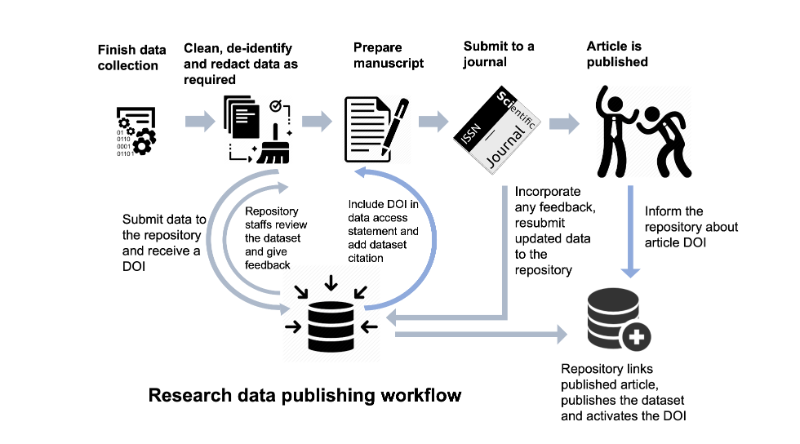
For researchers, it is important to choose a reliable data repository that provides a permanent identifier, such as a DOI (digital object identifier) to ensure long-term access to their data. Repository staff then check that the data and metadata (information about the data) meet relevant standards and inform the researchers of the outcome. Researchers usually publish their findings in the form of a primary research article that analyses their new data, but they can also use an existing dataset, known as secondary data reuse. In both cases, researchers should cite and add a reference to the dataset in a standard manner. This is essential to demonstrate compliance with funder mandates and to track how shared data has been used and reused. Journals need to make sure this requirement has been fulfilled where relevant. Below is a general data publishing workflow for institutional data repositories.
To understand current data citation and reuse practices, I led a case study of biodiversity datasets published via a well-known federated data repository, the Global Biodiversity Information Facility (GBIF) (Khan et al., 2021a). I found that openly available biodiversity data are being increasingly reused, where the number of citing articles increased from 0.6% in 2013 to 40.5% in 2018. A content analysis of a random sample of citing articles showed that 48% cited datasets in a standard manner that could be captured by an automated method. Among these, 32% of the articles mentioned the dataset in their reference lists and 16% included data access statements besides citing the dataset within different sections of the article. However, 25% mentioned the datasets in the methods section only within the text, which is difficult for indexing systems to find. Mentions in methods and supplementary material sections were also common (14%). I found similar results to a case study of primary human genome-wide association studies (GWAS) (Thelwall et al., 2020). Among 314 primary human GWAS papers, only 13% reported the location of a complete set of GWAS summary data, even though the percentage increased recently.
Proper data citation is the key to the efficient functioning of automated systems for detecting them, such as the Scholix (Scholarly Link Exchange) framework. In the first ever empirical case study of the Scholix API, I discovered nearly 1,500 new datasets for articles associated with University of Bath researchers (Khan et al., 2020). Despite the encouraging results, my analysis suggested that many of these links were created manually, rather than through automated capture from journal articles. Improved usability for such technological solutions would help data repository managers find links between articles and datasets and track secondary data reuse. In a survey of different types of data repositories (Khan et al., 2021b), I found that 32% reported tracking data reuse in some form, where 50% would like to do so. Repository managers also reported a lack of engagement from users and a lack of human resources as their top challenges. Given the current siloed nature of data repositories, the main recommendations for future repository systems are: integration and interoperability between data and systems (30%), better research data management tools (19%), tools that allow computation without downloading datasets (16%), and automated systems (16%). Funders should therefore consider these areas of support and improvements to value researchers’ effort to share data. This will also pave the way to develop meaningful metrics for research data and incorporate this in the academic reward system to further incentivize data sharing.
Nushrat Khan
https://orcid.org/0000-0002-4521-0920
https://www.researchgate.net/profile/Nushrat-Khan
References:
Thelwall, M., Munafò, M., Mas-Bleda, A., Stuart, E., Makita, M., Weigert, V., Keene, C., Khan, N., Drax, K. and Kousha, K. (2020), “Is useful research data usually shared? An investigation of genome-wide association study summary statistics”, Plos One, Vol. 15 No. 2, e0229578. https://doi.org/10.1371/journal.pone.0229578
Khan, N., Pink, C. J., & Thelwall, M. (2020), Identifying Data Sharing and Reuse with Scholix: Potentials and Limitations. Patterns, Vol. 1 No. 1, 100007.
Khan, N., Thelwall, M., & Kousha, K. (2021a). Measuring the impact of biodiversity datasets: data reuse, citations and altmetrics. Scientometrics, 126(4), 3621-3639.
Khan, N., Thelwall, M., & Kousha, K. (2021b). Are data repositories fettered? A survey of current practices, challenges and future technologies. Online Information Review.
For more information please contact the Corporate Communications Team.